CIFAR-10 — reproducing He et al. (2016)
examples/cifar/train_cifar_resnet56.py replicates the CIFAR-10 result
from Deep Residual Learning for Image Recognition (He et al., 2016):
6.97 % test error (~93 % top-1 accuracy) with ResNet-56, matching the
paper’s SGD recipe exactly.
It is the primary example of writing a custom MentorTrainer
that deviates from the built-in Adam + StepLR defaults.
# fresh run
python examples/cifar/train_cifar_resnet56.py
# resume, show progress bars
python examples/cifar/train_cifar_resnet56.py \
-resume_path ./tmp/resnet56.pt -epochs 200 -verbose true
Performance
Measured on an RTX 3090 (batch size 128, single GPU, < 1 GB GPU memory):
Metric |
Value |
|---|---|
Throughput |
~43 iterations / sec |
Total runtime |
~30 min (78 K iterations) |
Peak GPU memory |
< 1 GB |
Best validation accuracy |
~93.02 % |
The validation-loss curve below shows the characteristic three-step staircase produced by the iteration-based LR schedule:
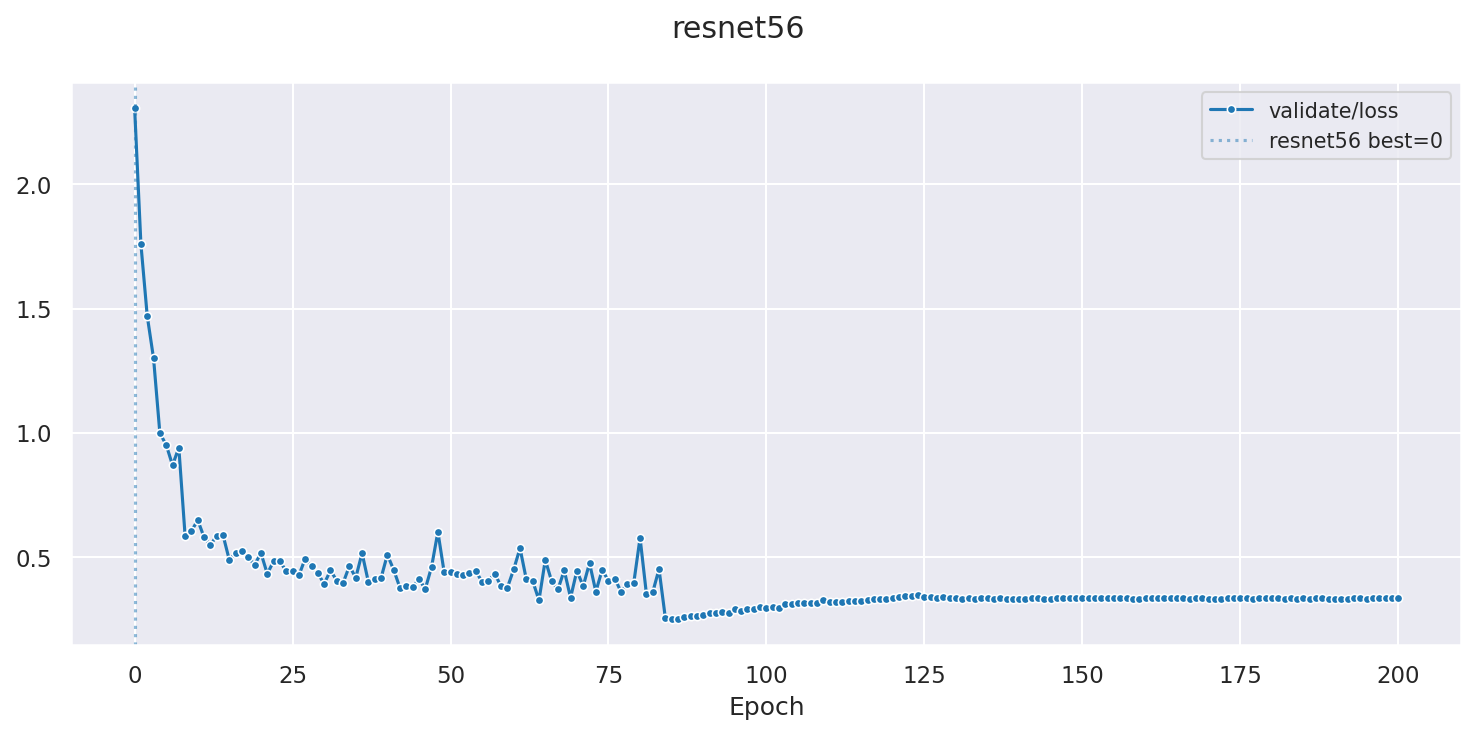
Validation loss over 200 epochs. The dotted vertical line marks epoch 0 (baseline before training); the three drops correspond to LR reductions at 32 K, 48 K, and 64 K iterations (~epochs 82, 123, 164).
Reproduce the plot from a finished checkpoint:
mtr_plot_file_hist -paths ./tmp/resnet56.pt -verbose \
-values validate/loss -output /tmp/cifar_56_loss.png
Key design decisions
SGD instead of Adam
: The built-in Classifier and
Regressor trainers use Adam.
CifarSGDResnetClassifier overrides create_train_objects to create
an SGD optimiser with momentum 0.9 and weight decay 1e-4 — the settings
from the paper. Assigning self.trainer = CifarSGDResnetClassifier() in
the model’s __init__ is sufficient; Mentee delegates
create_train_objects, training_step, and validation_step to the
trainer automatically.
Iteration-based LR schedule
: The paper’s milestones (32 K / 48 K / 64 K iterations) do not align with
epoch boundaries for all batch sizes. IterationMultiStepLR reads
total_train_iterations — a cumulative batch counter
maintained and checkpointed by Mentee — instead of
carrying its own state. state_dict() therefore returns {}, and
load_state_dict() simply re-derives the correct LR from the restored
counter. The schedule survives resume unchanged, even across machines or
batch-size changes.
First metric key is the principal metric
: default_training_step returns {"acc": acc, "loss": loss.item()} with
acc first. validate_epoch() always maximises the
first key when selecting the best checkpoint, so a higher-is-better metric
must come first. Putting loss first would cause the untrained model
(highest loss) to be permanently recorded as “best”.
Source
1#!/usr/bin/env python3
2"""CIFAR-10 with the original ResNet-56 architecture from He et al. (2016).
3
4The paper reports 6.97% test error for ResNet-56 on CIFAR-10. This script
5reproduces the training recipe: SGD + momentum, weight-decay 1e-4, and a
6multi-step LR schedule at 32K/48K/64K iterations (~82/123/164 epochs with
7batch_size=128 on 50K training samples).
8
9Architecture: ResNet-56 is a CIFAR-specific design (3x3 convs, no max-pool,
10global avg-pool before the classifier) using torchvision's BasicBlock.
11It is NOT the same as the ImageNet ResNet-50 / ResNet-101 variants.
12
13Usage:
14 python train_cifar_resnet56.py
15 python train_cifar_resnet56.py -resume_path ./tmp/resnet56.pt -epochs 200 -verbose
16"""
17import sys
18from pathlib import Path
19sys.path.insert(0, str(Path(__file__).resolve().parents[2]))
20
21from typing import Any, Dict, Optional
22
23import torch
24import torch.nn as nn
25import torch.nn.functional as F
26import torchvision
27from torch.utils.data import DataLoader
28from torchvision import transforms
29from torchvision.models.resnet import BasicBlock
30import fargv
31
32from mentor import Mentee
33from mentor.trainers import MentorTrainer
34
35
36# ---------------------------------------------------------------------------
37# Custom trainer: SGD + iteration-based LR (matches He et al. recipe)
38# ---------------------------------------------------------------------------
39
40class CifarSGDResnetClassifier(MentorTrainer):
41 """SGD + momentum + weight-decay + iteration-based LR decay for CIFAR.
42
43 Matches the training recipe in He et al. (2016):
44 lr=0.1, momentum=0.9, weight_decay=1e-4, divide LR by 10 at
45 32K, 48K, and 64K iterations (~82, 123, 164 epochs with batch 128).
46
47 The LR scheduler (IterationMultiStepLR) reads mentee.total_train_iterations
48 directly, so its state_dict() is empty -- no extra state to checkpoint.
49 Resume is automatic because total_train_iterations is persisted by Mentee.
50 """
51
52 class IterationMultiStepLR:
53 """LR scheduler that reads its state from mentee.total_train_iterations.
54
55 state_dict() returns {} -- all persistent state lives in the Mentee.
56 load_state_dict({}) re-applies the correct LR from the restored counter.
57 """
58
59 def __init__(
60 self,
61 optimizer: torch.optim.Optimizer,
62 mentee: Any,
63 base_lr: float = 0.1,
64 milestones: tuple = (32000, 48000, 64000),
65 gamma: float = 0.1,
66 ) -> None:
67 self.optimizer = optimizer
68 self.mentee = mentee
69 self.base_lr = base_lr
70 self.milestones = list(milestones)
71 self.gamma = gamma
72 self._apply_lr()
73
74 def _apply_lr(self) -> None:
75 done = self.mentee.total_train_iterations
76 factor = self.gamma ** sum(1 for m in self.milestones if done >= m)
77 lr = self.base_lr * factor
78 for pg in self.optimizer.param_groups:
79 pg["lr"] = lr
80
81 def step(self) -> None:
82 self._apply_lr()
83
84 def state_dict(self) -> dict:
85 return {}
86
87 def load_state_dict(self, state: dict) -> None: # noqa: ARG002
88 self._apply_lr()
89
90 def __init__(
91 self,
92 milestones: tuple = (32000, 48000, 64000),
93 momentum: float = 0.9,
94 weight_decay: float = 1e-4,
95 ) -> None:
96 super().__init__()
97 self.milestones = list(milestones)
98 self.momentum = momentum
99 self.weight_decay = weight_decay
100
101 @classmethod
102 def default_training_step(
103 cls,
104 model: Any,
105 batch: Any,
106 loss_fn: Optional[Any] = None,
107 ) -> tuple:
108 x, y = batch
109 x, y = x.to(model.device), y.to(model.device)
110 logits = model(x)
111 eff_fn = loss_fn if loss_fn is not None else F.cross_entropy
112 loss = eff_fn(logits, y)
113 acc = (logits.argmax(1) == y).float().mean().item()
114 return loss, {"acc": acc, "loss": loss.item()}
115
116 def create_train_objects(
117 self,
118 model: Any,
119 lr: float = 0.1,
120 step_size: int = 10, # unused -- kept for interface compatibility
121 gamma: float = 0.1,
122 loss_fn: Optional[Any] = None,
123 overwrite_default_loss: bool = False,
124 ) -> Dict[str, Any]:
125 if loss_fn is not None and (overwrite_default_loss or self._loss_fn is None):
126 self._loss_fn = loss_fn
127 elif self._loss_fn is None:
128 self._loss_fn = nn.CrossEntropyLoss()
129 self._optimizer = torch.optim.SGD(
130 model.parameters(),
131 lr=lr,
132 momentum=self.momentum,
133 weight_decay=self.weight_decay,
134 )
135 self._lr_scheduler = CifarSGDResnetClassifier.IterationMultiStepLR(
136 self._optimizer,
137 model,
138 base_lr=lr,
139 milestones=self.milestones,
140 gamma=gamma,
141 )
142 return {
143 "optimizer": self._optimizer,
144 "lr_scheduler": self._lr_scheduler,
145 "loss_fn": self._loss_fn,
146 }
147
148
149# ---------------------------------------------------------------------------
150# ResNet-56 model (uses torchvision BasicBlock)
151# ---------------------------------------------------------------------------
152
153class CifarResNet56(Mentee):
154 """CIFAR-10 ResNet-56 as described in He et al. (2016).
155
156 Architecture: 6n+2 layers with n=9 -> 56 layers.
157 Three groups of n BasicBlocks with 16, 32, 64 filters.
158 Global average pooling before the 10-class linear head.
159 """
160
161 def __init__(self, num_classes: int = 10, n: int = 9) -> None:
162 super().__init__(num_classes=num_classes, n=n)
163 self.conv = nn.Conv2d(3, 16, 3, padding=1, bias=False)
164 self.bn = nn.BatchNorm2d(16)
165 self.layer1 = self._make_group(16, 16, n, stride=1)
166 self.layer2 = self._make_group(16, 32, n, stride=2)
167 self.layer3 = self._make_group(32, 64, n, stride=2)
168 self.fc = nn.Linear(64, num_classes)
169 self.trainer = CifarSGDResnetClassifier()
170
171 def _make_group(self, in_ch: int, out_ch: int, n: int, stride: int) -> nn.Sequential:
172 downsample = None
173 if stride != 1 or in_ch != out_ch:
174 downsample = nn.Sequential(
175 nn.Conv2d(in_ch, out_ch, 1, stride=stride, bias=False),
176 nn.BatchNorm2d(out_ch),
177 )
178 blocks = [BasicBlock(in_ch, out_ch, stride=stride, downsample=downsample)]
179 for _ in range(n - 1):
180 blocks.append(BasicBlock(out_ch, out_ch))
181 return nn.Sequential(*blocks)
182
183 def forward(self, x: torch.Tensor) -> torch.Tensor:
184 x = F.relu(self.bn(self.conv(x)))
185 x = self.layer1(x)
186 x = self.layer2(x)
187 x = self.layer3(x)
188 x = F.adaptive_avg_pool2d(x, 1).flatten(1)
189 return self.fc(x)
190
191
192# ---------------------------------------------------------------------------
193# Data
194# ---------------------------------------------------------------------------
195
196def make_loaders(data_dir: str, batch_size: int, num_workers: int):
197 mean = (0.4914, 0.4822, 0.4465)
198 std = (0.2023, 0.1994, 0.2010)
199 train_tf = transforms.Compose([
200 transforms.RandomCrop(32, padding=4),
201 transforms.RandomHorizontalFlip(),
202 transforms.ToTensor(),
203 transforms.Normalize(mean, std),
204 ])
205 val_tf = transforms.Compose([
206 transforms.ToTensor(),
207 transforms.Normalize(mean, std),
208 ])
209 train = DataLoader(
210 torchvision.datasets.CIFAR10(data_dir, train=True, download=True, transform=train_tf),
211 batch_size=batch_size, shuffle=True, drop_last=True, num_workers=num_workers,
212 )
213 val = DataLoader(
214 torchvision.datasets.CIFAR10(data_dir, train=False, download=True, transform=val_tf),
215 batch_size=batch_size, shuffle=False, num_workers=num_workers,
216 )
217 return train, val
218
219
220# def main(epochs: int=200, batch_size: int=128, lr: float=0.1, resume_path: str="./tmp/resnet56.pt",
221# data: str="./tmp/data", device: str="cuda", verbose: bool=False, num_workers: int=2):
222# train_loader, val_loader = make_loaders(data, batch_size, num_workers)
223
224# model, opt, sched = CifarResNet56.resume_training(
225# resume_path,
226# model_class=CifarResNet56,
227# device=device,
228# lr=lr,
229# tolerate_irresumable_trainstate=True,
230# )
231
232# model.fit(
233# train_loader,
234# val_data=val_loader,
235# epochs=epochs,
236# lr=lr,
237# checkpoint_path=resume_path,
238# verbose=verbose,
239# )
240
241# best = model._validate_history.get(model._best_epoch_so_far, {})
242# print(f"\nBest epoch {model._best_epoch_so_far}: "
243# f"acc={best.get('acc', 0):.4f} "
244# f"error={100*(1-best.get('acc', 0)):.2f}%")
245
246
247# if __name__ == "__main__":
248# p, _ = fargv.parse_and_launch(main)
249
250
251def main():
252 args, _ = fargv.parse({
253 "epochs": 200,
254 "batch_size": 128,
255 "lr": 0.1,
256 "resume_path": "./tmp/resnet56.pt",
257 "data": "./tmp/data",
258 "device": "cuda",
259 "num_workers": 2,
260 "wandb": False,
261 "gradio": False,
262 })
263 print(f"Training CIFAR-10 ResNet-56 with args: {args}", flush=True)
264 train_loader, val_loader = make_loaders(args.data, args.batch_size, args.num_workers)
265 model, opt, sched = CifarResNet56.resume_training(args.resume_path, device=args.device, lr=args.lr)
266 model.fit(
267 train_loader,
268 val_data=val_loader,
269 epochs=args.epochs,
270 lr=args.lr,
271 checkpoint_path=args.resume_path,
272 verbose=args.verbosity > 0,
273 report_wandb=args.wandb,
274 report_gradio=args.gradio,
275 )
276
277
278if __name__ == "__main__":
279 main()